LADFN: Learning Actions for Drift-Free Navigation
/ 2 min read
In dynamic urban environments, autonomous vehicles face significant challenges in maintaining localization accuracy due to the presence of moving obstacles such as pedestrians and traffic. LADFN (Learning Actions for Drift-Free Navigation) is a novel reinforcement learning framework I co-developed to directly address this issue by optimizing autonomous navigation policies for reduced drift in state estimation. Our system integrates perception-aware motion planning with Proximal Policy Optimization (PPO) and demonstrates a principled solution to reduce Absolute Trajectory Error (ATE) in highly dynamic scenes.
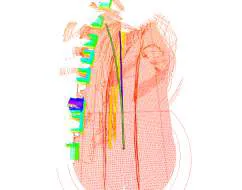
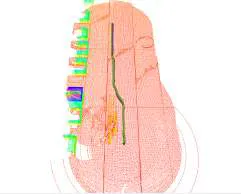
The central problem addressed by LADFN is the accumulation of drift in odometry-based localization systems, particularly in the presence of moving vehicles that disrupt sensor readings. We adopt Velodyne-16 3D LIDAR as the primary sensing modality and use LOAM (Lidar Odometry and Mapping) for baseline state estimation. Through experimentation, we found that conventional controllers like the Stanley controller, even when aided by dynamic object filtering, fail to maintain localization fidelity under such conditions.
I helped define the Markov Decision Process (MDP) that underpins the LADFN policy. This involved carefully designing a state space that encodes ego-vehicle position, feature-rich regions, and the dynamics of surrounding traffic agents. I co-developed a novel reward function that jointly incentivizes movement towards LIDAR-friendly, texture-rich areas and avoidance of dynamic obstacles — maximizing perception quality while maintaining safe, efficient trajectories.
Our system architecture comprises four key modules:
- Perception and obstacle filtering using LOAM and CARLA’s semantic LIDAR segmentation
- Waypoint generation via PPO-based policy inference,
- Cubic spline trajectory interpolation, and
- Path tracking using the Stanley Controller.
I was responsible for implementing and training the PPO agent using the Stable-Baselines3 library. To enable sample-efficient training, we simulated numerous environments with varying initial states and traffic configurations in CARLA, including both static and dynamic scenes. I also helped design the episodic structure for training rollouts, ensuring meaningful feedback via termination conditions such as boundary violations and collisions.
Through extensive testing across five CARLA scenes, LADFN showed consistent improvements over the benchmark controller. Our method reduced average trajectory drift by up to 4.8× and final rotational error by over 2×, even in the presence of dynamic traffic and without relying solely on obstacle filtering. We verified that the ego vehicle, under LADFN control, actively sought texture-rich areas and maintained safer distances from traffic, significantly boosting the accuracy of LIDAR-based mapping.
This work was conducted in collaboration with the Robotics Research Center at IIIT Hyderabad and the ECE Department at UT Austin.
 |  |
|---|---|
 |  |